Learnings from gRPC on AWS
At Rokt, we’ve been using RESTful JSON/HTTP/1.1 for communication between our services hosted on AWS. As we move towards a microservice-centric architecture, we introduce more requests between these smaller, isolated services to perform a transaction or operation. These requests incur latency in the form of network calls and serialization and deserialization times. The more inter-service requests that are performed, the more latency is accumulated. This is significant for our consumer-facing services due to the high volume of traffic; and the latency-sensitive nature of our business. In an attempt to mitigate this, we investigated the use of gRPC to see if it offered a more efficient transport mechanism between our services.
gRPC leverages Protocol Buffers and HTTP/2 for efficient, multiplexed communication between services. gRPC itself introduces a highly performant and heavily benchmarked web server, an IDL for generating client and server stubs, bidirectional streaming, thick client load balancing, status codes specific to microservices, deadlines and timeouts and pluggable auth, tracing, load balancing, and health checking. The creators of gRPC define it as “A modern, open source, high-performance remote procedure call (RPC) framework that can run anywhere. It enables client and server applications to communicate transparently, and makes it easier to build connected systems.”
At first, we used gRPC between a monolithic EC2 application (client) and one of our newly created containerised microservices (server) hosted on Amazon ECS. The existing service used the standard HTTP/1.1 transport protocol. Adopting gRPC in the services was trivial due to the way gRPC piggybacks off the Protocol Buffers IDL. Messages and services are defined in a .proto file, and then the client and server stubs are generated in any of the many supported languages using the protocol buffer compiler (protoc).
Getting a client to talk to a server using gRPC was simple enough however, we ran into a bunch of issus when we tried to deploy this on AWS, particularly around load balancing. For load balancing HTTP/1.1 requests we use AWS’s L7 Application Load Balancer (ALB). With ALB, a client sends request to the ALB via HTTP/1.1 and then the ALB forwards the request to the backend targets to distribute the load. Unfortunately, with gRPC, it was not as simple because gRPC uses HTTP/2. The AWS ALB only supports HTTP/2 from client to ALB. The ALB then downgrades the request to HTTP/1.1 before forwarding it through to the backend target. Additionally, AWS ALB lacks support for HTTP trailers. Full support for HTTP/2 and trailers is required for gRPC to function. This left us with two options: spin up our own HTTP/2 compliant load balancer (e.g. Envoy, Nginx), or, use one of AWS’s lower-level, L4 Load Balancers such as the Elastic Load Balancer, ELB, or the newer Network Load Balancer, NLB. We decided to try load balancing gRPC using the newer AWS NLB.
This should have worked well for our ECS hosted microservices as NLB supports dynamic port mapping. However, we encountered several problems with NLB. First, security groups can not be set on an NLB, which makes it very difficult for the backend instances to define security groups to control incoming network traffic. A workaround was proposed, however it relies upon some AWS cli hacks which is less than ideal. The second problem we ran into was that traffic from VPC Peering (non-Nitro instances) is not allowed. This forbids cross-region API calls and makes troubleshooting a huge pain. Last but not least, we quickly discovered one major flaw in this plan: NLB does not support hairpinning of requests. This is a show-stopper for our ECS-based services where multiple services can be hosted on the same ECS cluster instance. Services hosted on the same instance would not be able to communicate between themselves without hairpinning of requests in and out of the same load balancer. As there is no workaround for this issue, we had to drop the idea of using NLB completely.
Next, we decided to try the older Elastic Load Balancer (ELB) in AWS. However, ELB does not support dynamic port mapping, and so when the container is spun up, it would need to be on a fixed port. This restricts the number of container instance of a particular service to the number of underlying EC2 instances which is a major scaling limitation. Each service would need to have its port allocated in a static manner (for example via a hardcoded value in CICD). This would make deployment management quite a headache. We tried out a simple workaround whereby we spun up a Nginx container with a fixed port, and then used it to proxy requests to containers on the same host via docker container links. This was not great as we had to incur the latency and overhead of two load balancers before we hit our target. The load balancer container and service container also had to be part of the same ECS task definition. Due to a limitation in ECS, the two can not scale independently resulting in a static ratio of load balancer containers to back end containers. It’s also important to note that the, Docker container link feature we relied upon here is a legacy feature and may be removed in future releases.
Choosing an L4 LB could be problematic for another two reasons: SSL termination is now on the target itself which introduces the challenge of managing certs and, the LB will only round-robin TCP connections and not individual requests. That is, we would have to open many connections on the client side in the hopes that we hit all the targets, and we would have to actively recycle connections to let in new targets. This adds additional complexity to the client and increases the risk of uneven distribution of load to the targets. The whole point of HTTP/2 was to multiplex and keep connections to a minimum to avoid costly SSL handshakes, but now we would need to do client-side load balancing and server-side load balancing just to achieve that efficiency.
Benchmarking gRPC
The following benchmarks are based off round-robining Nginx container instances with the following infrastructure:

The monolith was stress tested for an hour with 4x production load. For each request, two concurrent calls were made: one to the existing HTTP/1.1 service and the other to the Nginx + gRPC service.
Average Response Times
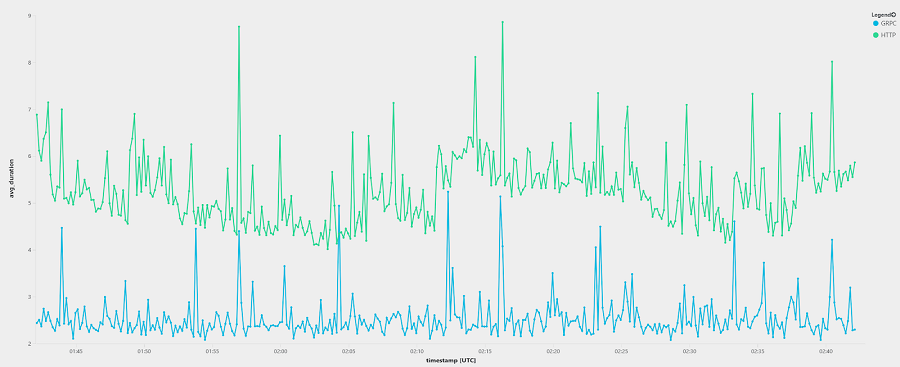
gRPC on average was 2x faster than HTTP/1.1
P99.99 Response Times
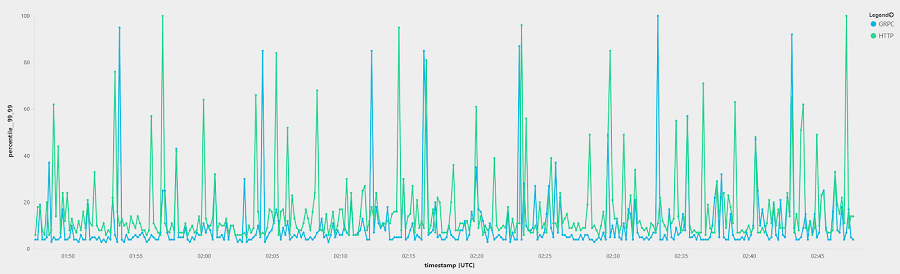
At the 99.99th percentile, gRPC trended below HTTP/1.1, though both saw their fair share of spikes.
Count of Response Times over the Service SLA
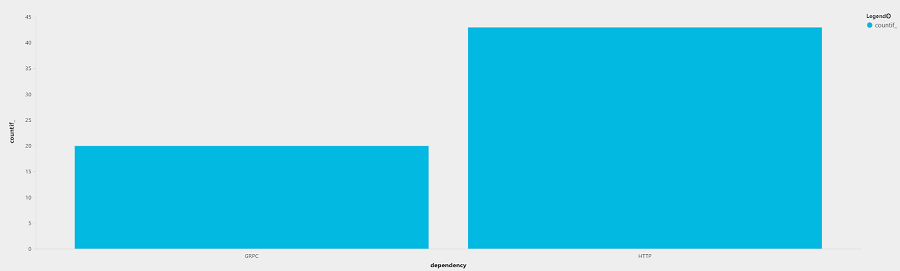
With an SLA of 100ms, requests timed out 50% less using gRPC than using HTTP/1.1.
HTTP/1.1 Response Time Distribution
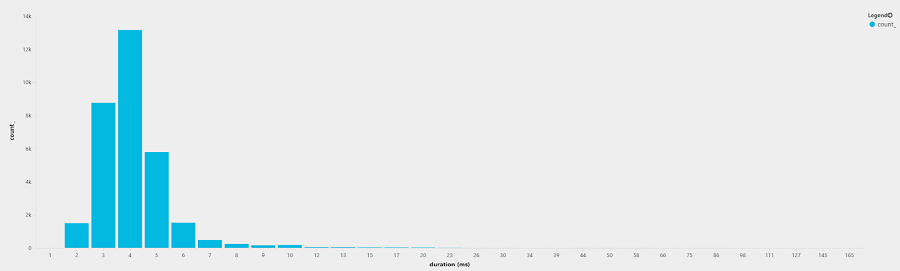
The majority of the requests fell between 3-5 ms response times.
gRPC Response Time Distribution
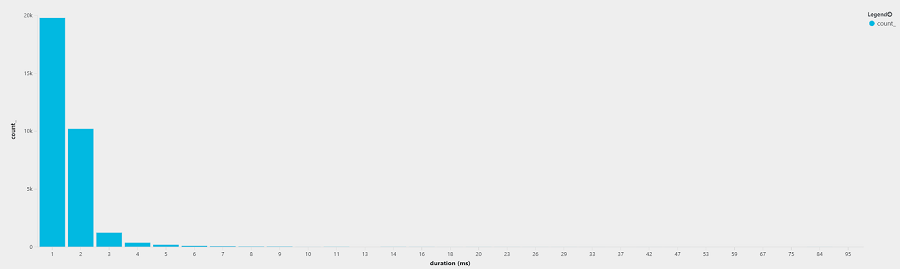
The majority of requests fell between 1-2 ms response times.
Conclusion
Using gRPC on AWS has some major challenges. Without full HTTP/2 support on AWS Application Load Balancer, you have to spin up and manage your own load balancers. Neither NLB and ELB are viable alternatives on AWS due to issues with traffic to and from the same host, dynamic port mappings, SSL termination complications, and sub-optimal client and server-side round-robining of TCP connections.
gRPC demonstrated performance improvements, however it would take considerable infrastructure efforts to adopt, whether it be using LBs such as Nginx or Envoy; or setting up a service mesh with something of the likes of Istio. Another possibility would be to make use of thick client load balancing, though this would also require additional service discovery infrastructures such as Consul or ZooKeeper.
We will continue to monitor gRPC on AWS and hope that AWS ALB will fully support the HTTP/2 spec soon! In the meantime, we have adopted protocol buffers and HTTP/2 for our real-time interservice communication to realize efficiency gains. Protocol buffers give us efficient serialization and deserialization; and HTTP/2 allows our client to open only one connection to an ALB and have messages multiplex, which reduces costly SSL handshakes.